
这是一个创建于 2958 天前的主题,其中的信息可能已经有所发展或是发生改变。
马辰龙,负责某大型网页游戏平台的运维开发,专注于运维自动化、监控系统故障自愈研究,擅长 Perl 开发、正则表达式、日志精确匹配。

网络游戏是对用户体验要求最严苛的 IT 行业之一,任何 IT 问题造成的业务不稳定,都可能导致玩家的流失,进而影响游戏商的营收。因此,自动化运维对于游戏平台的重要不言而喻,各种 DevOps 产品和自动化运维技术方案不断涌现,包含发布变更、容量伸缩、故障自愈等多种场景的游戏运维技术日趋成熟,这些改变都让运维工作流程越来越简化。
然而流程的简化并不意味着运维变得容易,恰恰相反随着云计算、移动互联网的广泛应用,游戏业务对运维的要求水涨船高!相比起对 IT 基础设施运维操作的需求,业务侧更需要运维提供高质量的业务保障服务,包括对业务架构及部署的持续优化,精细化的游戏健康度管理,以及快速的故障处理服务等。
以下就是由马辰龙先生为我们分享他在日常工作中总结的《游戏平台运维自动化扩展之故障自愈》:
大家好,我们用一个例子作为今天分享的开始,越来越复杂的网络问题常常会造成各种误报,导致各种误报信息的轰炸,出现报警我们一般先看报警内容,这种情况大家都遇到过吧?久而久之就造成了对告警信息的麻木。比如凌晨 2 点某机房切割网络抖动,一下过来几百条告警短信,相信大家不可能一条条的看。
首先我们要解决的是误报的问题。现在的监控软件无非就是 Zabbix 、 Nagios 或者 SmokePing 这类,还会有一些单点监控软件。如果想消除误报只有多 IDC 去部署监控服务器,搭建多节点去监控网络问题,但这就需要使用大量的服务器资源,有没有什么好的解决方案呢?而且即使我们搭建了大量的监控服务器,又怎么去集中处理告警消息呢? 经过对市面上流行的监控类产品进行广泛调研,发现云智慧的监控宝可以通过分布式监测节点,多区域同时监控服务器、网站的健康状况,同时还提供一些国外节点(我们的业务涉及海外)监测海外用户的业务访问体验,而且阈值和监控方式也可以根据业务的实际需求去自定义。
当然作为一个崇尚运维自动化的运维人员,我看中的不仅是这些,更重要的是能够 callback 告警消息。如果是因为服务器网络或者其他原因导致宕机,在收到告警消息之后,让后端系统能够根据消息去自动处理是不是会更好呢。给大家看一副图来理解下:
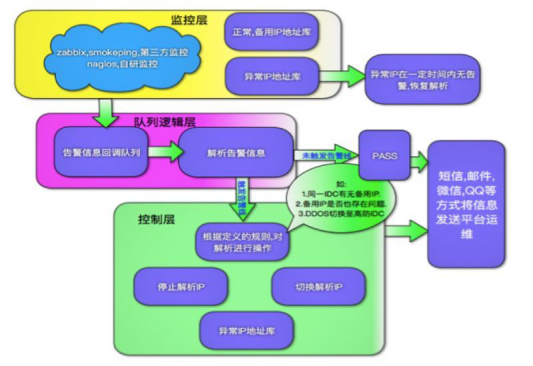
根据回调信息,事先将其定义成一些规则,当我们匹配到了告警信息中的特定信息可以自主切换。 监控宝的 URL 回调可以在这里设置:
运维监控的发展:
过去: Nagios 、 Cacti 、 Zabbix 监控单一,对告警后知后觉;
现在: API 监控数据聚合、告警信息收敛,自动化感知;
未来:挖掘故障信息,制定故障自愈规则,提前感知。
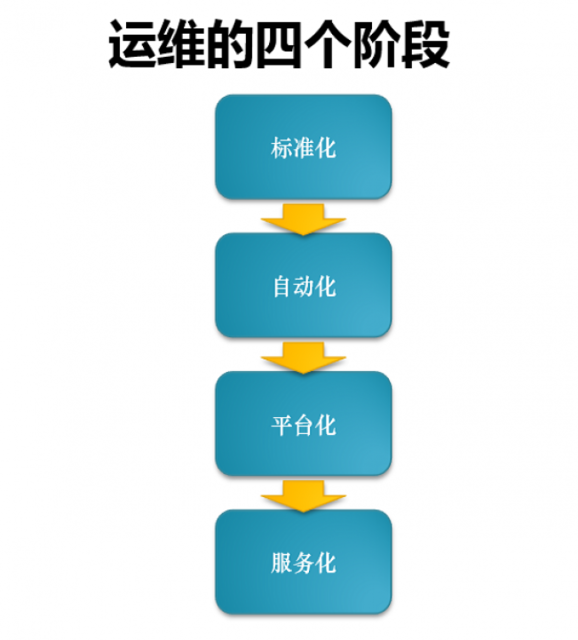
运维的建设有四个阶段,简称为四化建设:第一个阶段就是标准化。标准化的意思是把主机名、内网以及配置文件统一起来,如果不统一,后面的东西就无法继续。没有一个标准化的环境,脚本是无法写下去的。第二个阶段是自动化。中小型企业阶段都是自动化到平台化的过渡,平台化就是把自动化的东西分装,把功能整合,把数据做聚合,然后放在平台上来可视化。第三个阶段是平台化。以后的趋势是脚本和功能必须是外部化的,这样新来的一个人才能接手。不用在服务器上跑脚本,还要同下个人交代在哪儿装。最后一个阶段就是服务化。服务化是指现在云平台所承载的东西。举个例子,搭一个 redis 集群,用户不需要知道服务器有多少个,因为所提供的 NOSQL 服务打开后,用户就可以直接使用了。
所以我们未来要做的就是收集告警信息进行自动化处理,而不是通知运维上线处理。我们要脱离那种每天等着告警信息去处理故障,要主动出击,不要等到故障了再去处理,而且即使事后处理好了,那么时间成本也是很高的。 再举个栗子,一个网站在全国各地会解析为多个 IP ,而且还会有备用 IP 用来切换(被 DDOS 的时候, IP 被封,我们需要切换)。我们会有一个脚本去检测这些 IP 的状态,当这些 IP 正常的时候才会切换到这些 IP 上,如果 Ping 不通或者有其他故障就不会去切换,否则去切换一个故障 IP 不是没有用吗?
我们在做监控的时候需要考虑很多不可控的因素,因此在写代码的时候要首先考虑异常状态,否则会造成二次故障,这是我们不愿意看到的。当故障 IP 2 小时内不丢包,我们就把他去掉,下次切换的时候就可以用到,反之亦然。这里提示下,对于这种时间周期可以使用 redis , expire 指定 ttl 。 给大家一张图来理解下告警信息的分类:
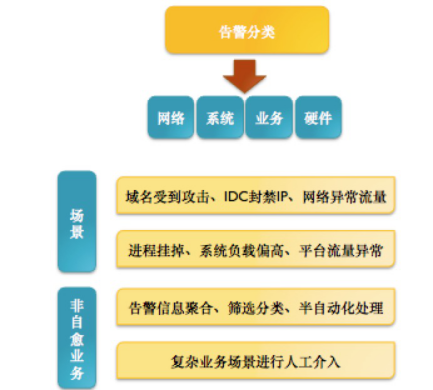
我们要做到能自动化的尽量自动化,不能自动化的我们要让它半自动,人工介入处理是最后的方案,因为是人就会犯错,尤其在业务出现异常,操作都是不可控的。 说这么多 ,核心就是需要建立自己的消息处理中心来分析问题,充分利用告警信息,大概的模型可以是这样:
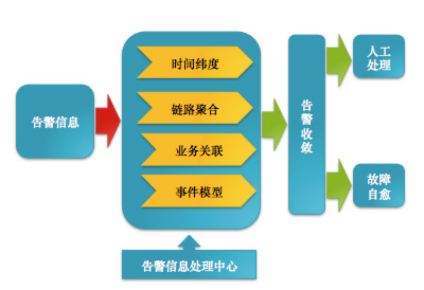
最后,故障自愈能够给我们带来什么:
1 、非工作时间运维人员处理故障以及响应时间;
2 、减少直接的线上操作、避免出现人为原因的二次故障;
3 、提高运维人员对故障原因的分析、以及工作积极性;
4 、提升运维的自身价值。
Q&A
问:如何做告警收敛?
答:比如我们以一台服务器为单位,每分钟的告警信息分为系统和网络告警,统一处理。(当然也能以收件人,业务关联为单位。)
问:对于传染型的故障,不知道有没有什么好的方案呢,就是反复访问一个问题导致骨牌性的反应。
答:比如网站报了 500 错误,那么我们发现 500 错误的时候,在告警的时候可以让它去错误日志里收集关于相同 IP 的 error ,一起发送。
问:怎么自动化的?
答:减少我们去服务器查日志的时间,频繁的 grep xxx 。
问:百度爬虫并发大没抗住,怎么自动化处理?
答:首先你是想让它爬还是不爬,不爬就匹配 useragent 。
问:你们故障自愈是哪些情况?是通过日志?还是 api url 监控?通过特定故障返回特定值??因为 java 的日志各种情况都有。
答:面对 DDOS 流量型攻击,通过分析 url 使用防火墙封禁,首先是日志。
问: DDOS 怎么分析 url ??有什么特征吗??
答: DDOS 是没有日志的,可以通过网络告警去触发, CC 攻击分析你的 URL ,规则可以自己去定义,有些注入、刷 API 等通过正则去匹配。运维人员要利用好日志,所有的问题都是从日志中分析行为发现的。
问:我们上了 ELK , Java 除了假死自动重启,好像没什么自愈的。
答: ELK 可以使用 API 拉日志,去分析业务的运行状态, ELK 的面太大,这里细节就不多说了。
目前尚无回复